Unlike most methods used in machine learning, the Random Forest algorithm does not require complex theory. In this material, we describe its features and applications.
Random Forest is an universal machine learning algorithm uses an ensemble of decision trees. The decision tree itself provides a very low quality of classification, but in reason of the large number of them, the result is greatly improved. It is also one of the few algorithms that can be used in the vast majority of applications.
What tasks are used for?
Due to its flexibility, Random Forest is used for almost any kind of machine learning problem. This includes classifications (RandomForestClassifier) and regressions (RandomForestRegressor), but also more complex tasks like feature selection, outlier/anomaly detection and clustering.
The main field of using the random tree algorithm is the first two items, other tasks are based on them. For the feature selection task, we implement the following code:
import pandas as pd
from sklearn.ensemble import RandomForestClassfier
from sklearn.feature_selection import SelectFromModel
X_train,y_train,X_test,y_test = train_test_split(data,test_size=0.3)
sel = SelectFromModel(RandomForestClassifier(n_estimators = 100))
sel.fit(X_train, y_train)Here we simply add a method to select the features based on the classification.
Procedure in the algorithm
- Load your data.
- Define a random sample in the given data set.
- The algorithm will then build a decision tree based on the sample.
- The tree is built until there are no more than n objects in each leaf, or until a certain height is reached.
- Then a prediction result will be obtained from each decision tree.
- At this point, voting will be done for each predicted result: we choose the best feature, do a split in the tree by it and repeat this point until the sample is exhausted.
- At the end, the prediction result with the highest number of votes is selected. This is the final prediction result.
The theoretical component of the random tree algorithm
Compared to other machine learning methods, the theoretical part of Random Forest algorithm is simple. We do not have a large amount of theory, only the formula for the final classifier a(x) is needed:
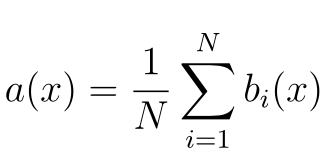
where
- N is the number of trees;
- i – counter for trees;
- b – decisive tree;
- x – our data-generated sample.
It is also worth noting that for the classification problem, we select the solution by majority voting, while in the regression problem we choose the mean.
Implementation of the Random Forest algorithm
We implement the algorithm using a simple example for the classification problem, using the scikit-learn library:
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criter
ion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1,
min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=Non
e, min_impurity_split=1e-07, bootstrap=True, oob_score=False, n_jobs=
1, random_state=None, verbose=0, warm_start=False, class_weight=None)Work with the algorithm following the standard scikit-learn routine. We calculate the AUC-ROC (area under the error curve) for the training and test parts of the model to determine its quality:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import roc_auc_score
# next - (X, y) - for training, (X2, y2) - for control
# model - regression
model = RandomForestRegressor(n_estimators=10,
oob_score=True,
random_state=1)
model.fit(X, y) # training
a = model.predict(X2) # prediction
print ("AUC-ROC (oob) = ", roc_auc_score(y, model.oob_prediction_))
print ("AUC-ROC (test) = ", roc_auc_score(y2, a))Required parameters of the algorithm
The number of trees – n_estimators
The more trees, the better the quality. It is worth noting that the adjustment and running time of Random Forest will increase proportionally, which can affect the performance.
Often with large increase of n_estimators quality on the training sample can even reach 100%, while quality on the benchmark reaches asymptote, which signals an overtraining of our model. The best way to avoid this is to estimate how many trees you need by fixing the moment when the quality of the test is not yet stable.
Split criterion
Also one of the most important parameters to build, but without much choice. The sklearn library implements gini and entropy criteria for classification tasks. They correspond to the classical splitting criteria: gini and entropy.
In turn, two criteria (mse and mae), which are functions of Mean Square Error and Mean Absolute Error, respectively, are implemented for regression problems. The mse criterion is used in almost all tasks.
A simple brute-force method will help to choose what to use to solve a particular problem.
Number of features to select splitting – max_features
If max_features is increased, the construction time of the forest increases, and the trees become similar to each other. In classification problems it is equal by default to
sqrt(n) , in regression problems it is equal to n/3 .It is one of the most important parameters in the algorithm. It is set up first, once we have defined the type of our task.
The minimum number of objects for splitting – min_samples_split
Secondary parameter, it can be left in default state.
Limiting the number of objects in the leaves – min_samples_leaf
Similar to min_samples_split , but by increasing this parameter the quality of the model in training decreases, while the time to build the model is reduced.
Maximum tree depth – max_depth
The shallower max_depth is, the faster the random tree algorithm is built and runs.
Increasing the depth dramatically increases the quality of both model training and model testing. If you have possibility and time to build deep trees, it is recommended to use maximum value of this parameter.
Shallow trees are recommended for tasks with a significant number of noise objects (outliers).
Advantages of the algorithm
- Has high prediction accuracy, which is comparable to gradient boosting results.
- It does not require careful parameter tuning and works well out of the box.
- Virtually insensitive to outliers in the data due to random sampling.
- Not sensitive to scaling and other monotonic transformations of trait values.
- Rarely gets overfitted. In practice, adding trees only improves the composition.
- If there is an overfitting problem, it is overcome by averaging or combining results from different decision trees.
- Able to efficiently handle data with a large number of features and classes.
- Handles missing data well – maintains good accuracy even when missing data is present.
- Handles both continuous and discrete features equally well
- Highly parallelisable and scalable.
Disadvantages of the algorithm
- The random tree algorithm requires a significant amount of computational resources to implement.
- The size of the models is large.
- Building a random forest is more time consuming than decision trees or linear algorithms.
- The algorithm is prone to over-learning on noisy data.
- There are no formal inferences, such as p-values, that are used to estimate the importance of variables.
- Unlike simpler algorithms, random forest results are more difficult to interpret.
- When there are very many sparse features in a sample, such as texts or sets of words (bag of words), the algorithm performs worse than linear methods.
- Unlike linear regression, Random Forest has no extrapolation capability. This can be considered a plus, as in case of outliers there will be no extreme values.
- If the data contains groups of features with correlation that have similar significance for the labels, small groups are favoured over large groups, leading to under-learning.
- The forecasting process using random scaffolding is very time consuming compared to other algorithms.
Conclusion
Random Forest method is an all-in-one machine learning supervised algorithm. It can be used in many problems, but it is mainly used in classification and regression tasks.
Effective and easy to understand, the algorithm has the significant disadvantage of being noticeably slower when the parameters within it are adjusted in some way.
You can use Random Forest if you need extremely accurate results, or if you have a huge amount of data to process, and you need an algorithm strong enough to handle all the data efficiently.