Naive Bayes classifier is a very popular algorithm in machine learning. It is mainly used to obtain the basic accuracy of a dataset. We will learn about its advantages & disadvantages and implement it in Python.
What is it?
Naive Bayes is the simplest algorithm you can apply to your data. As the name implies, this algorithm makes the assumption that all variables in the dataset are “naive”, i.e. not correlated with each other.
Suppose you see something green in front of you. This green object could be a hedgehog, a dog or a ball. Naturally, you will assume that it will be a ball. But why?
You create an algorithm and your goal is the problem above: to classify the object between a ball, a hedgehog and a dog. First you will think about defining the symbols of the object and then you will think about matching them with the objects of the classification, for example if the object is a circle it will be a ball, if the object is a prickly living thing it will be a hedgehog, and if our object barks it will probably be a dog.
The reason is simple: we have seen a green ball since childhood, but a dog or a hedgehog of that colour is highly unlikely to us. So, in our case, we can classify the object by matching its features with our classifier individually. Green was matched with a hedgehog, a dog and a ball, and we ended up with the highest probability of the green object belonging to the ball. This is the reason why we classified it as a ball.
The theoretical part of the algorithm
Bayes’ theorem calculates the posterior probability P(A | B) based on P(A), P(B) and P(B | A).
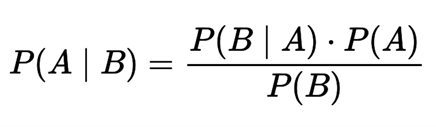
Where:
- P(A | B) is the posterior probability (that A of B is true)
- P(A) is the a priori probability (independent probability of A)
- P(B | A) is the probability of a given feature value at a given class (that B of A is true)
- P(B) is the a priori probability at a value of our trait. (independent probability of B).
Implementation in Python
### Load libraries & data
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from scipy.stats import norm
data = load_iris()
X, y, column_names = data['data'], data['target'], data['feature_name
s']
X = pd.DataFrame(X, columns = column_names)
### Split the data
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(X, y, random_state=
44)The result of the code:
0.9210526315789473
0.9210526315789473
The basic model with the simplest setting gives us an accuracy of more than 90% on the task of classifying iris flowers.
Pros and cons
Pros:
- The algorithm predicts the class of the test dataset easily and quickly. It also handles multi-class prediction well.
- The performance of naive Bayesian classifier is better than other simple algorithms such as logistic regression. Moreover, you need less training data.
- It works well with categorical features (compared to numerical features). For numerical traits a normal distribution is assumed, which can be a serious assumption in the accuracy of our algorithm.
Cons:
- If a variable has a category (in the test dataset) that was not observed in the training dataset, the model will assign 0 (zero) probability and cannot make a prediction. This is often referred to as the null frequency. To solve this problem, we can use a smoothing technique. One of the simplest smoothing techniques is called Laplace estimation.
- The predicted probability values returned by the predict_proba method are not always accurate enough.
- A limitation of this algorithm is the assumption of feature independence. However, in real-world problems completely independent features are very rare.
Where to use?
The naive Bayes algorithm is a classifier that learns very quickly. Consequently, this tool is ideal for making real-time predictions.
Also, this algorithm is also well known for its multi-class prediction feature. We can predict the probability of multiple classes of the target variable.
Thus, the ideal areas for application of naive Bayesian classifier are:
- Recommendation system. By combining the algorithm with Collaborative Filtering techniques, we can create a recommendation system that uses machine learning and data mining techniques to account for unseen information (such as user search for movies and viewing duration). The goal is to predict whether the user will like the resource/product or not.
- Spam filtering and text classification. Naive Bayesian classifier is mainly used to classify texts (due to better results in multi-class problems and independence rule) and has higher accuracy than other algorithms. As a result, it is widely used in spam filtering (in email) and sentiment analysis (e.g. social media, to detect positive and negative customer sentiment).
In this tutorial you learned about the naive Bayesian classification algorithm, its work, problems, implementation, advantages and disadvantages.
At the same time you also learned how to implement it in Python. Naive Bayesian classifier is one of the simplest and most efficient machine learning algorithms.
Despite significant advances in other methods over the last few years, Bayesian still proves its worth. It has been used successfully in many applications, from text analytics and spam filters to recommendation systems.